· 3 min read
Lessons Learned from my first Deep Learning contest
Game of Deep Learning was an image recognition challenge on AnalyticsVidya. The task was to classify 5 different types of Ships (Cargo, Military, Carrier, Cruise, and Tankers)

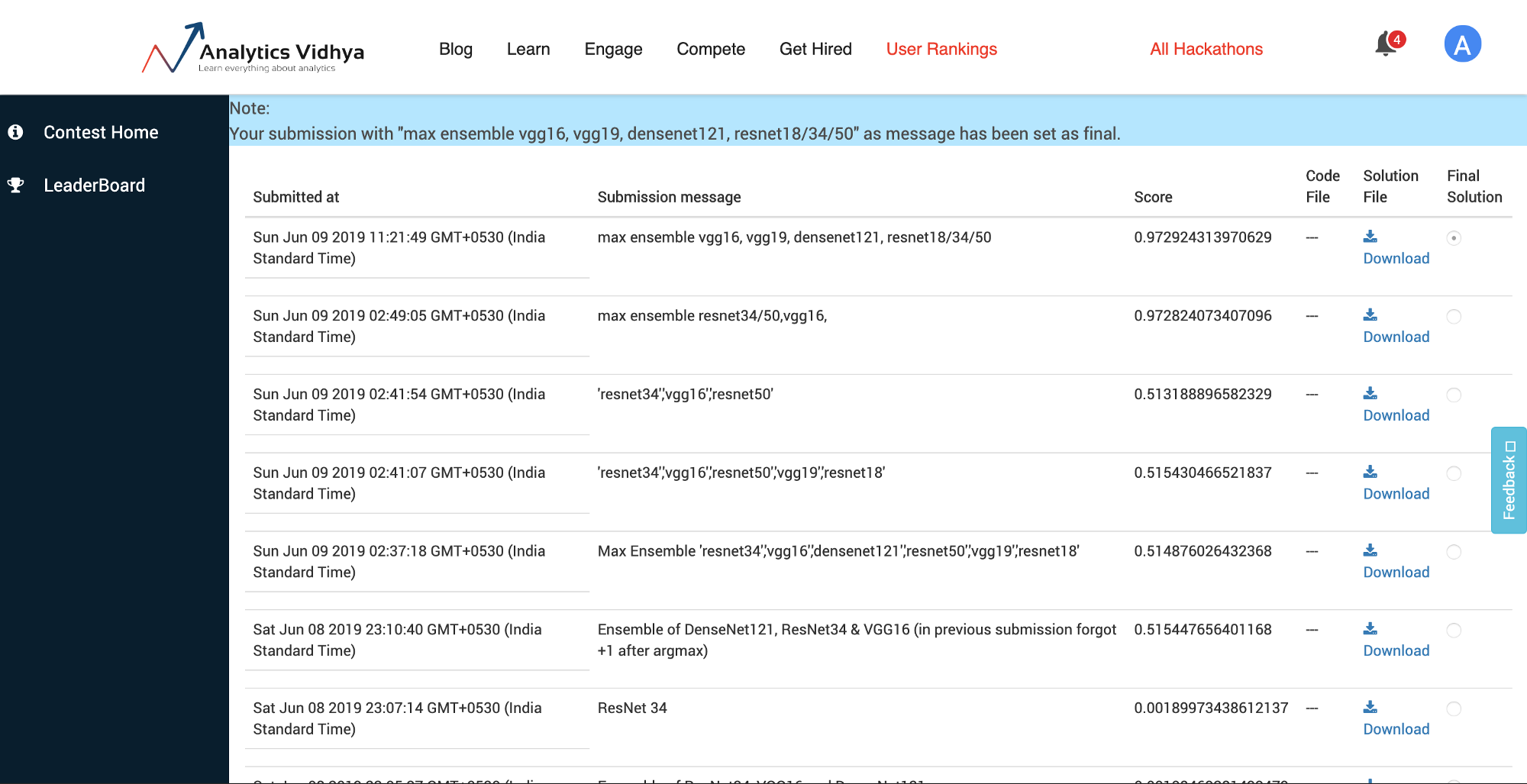
My rank is 41 out of 441. (0.97 F1 Score).
Before this, I had only practiced 2 lessons from Fast.ai and watched the first 5 lessons.
After the contest, I saw other participant’s approaches and found that their approach was much clearer and cleaner than mine.
Therefore, I decided to complete Fast.ai’s Deep Learning for Coders.
The contest was a month ago from this writing. I had the time to really sit and figure out what went well and what didn’t.
Approach
Here was my approach which I did in stages:
Step 1: Make models
1. Make a simple resnet50 model. And make sure input and output submission file are correct.
2. Improve the model. I found that the images were black and old. But the number of images were less and we cannot use external data so my solution was.
-
Heavy data augmentation (warping, crops, rotations): lead to 5—7 percent increase in F1 score and accuracy.
-
Progressive increase image size.
-
I initially started with (50,70) images
-
Trained it that then increased it. Trained it again.
3. Training approach.
- Freeze the model train for 4 epochs
- Unfreeze the model train for 7 epochs
- I found unfreezing was getting higher accuracy but only when done more than freeze training. 7 is what I stuck at.
- I replicated the kernel and trained resnet18, resnet34, vgg16, vgg19 and densenet121 so that I can ensemble there outputs
- Model Making Environment: Kaggle Code at Models directory
Step 2: Max Ensemble
After I had all the outputs from different models.
I used the output CSVs to make a max ensemble.
(You will see that I have renamed file names to be ‘modelname’.csv in ensemble folder and the output file is ‘simple.csv’)
Ensemble making environment: Local
Code: ankschoubey/AnalyticsVidya_Game_Of_Deep_Learning
Lessons and Mistakes Learned
Code
Environment
-
I trained on Kaggle Kernel. The only way to get output files was to commit.
-
I also did not load existing models because on Kaggle you have to attach it as a dataset and then load. It’s a pain so I did not bother.
-
It would have been much easier to train on Google Cloud, Collab or Clouderizer.
Should have used discriminative learning rate.
- Transfer learning without discriminative learning rate is stupid.
Refactor code early before replicating the kernel
-
I replicated kernels so that I can train different models on different kernels and get results faster.
-
The problem was that I had introduced a bug which got replicated. Also, making changes was a pain because I had to copy paste things multiple times.
Use metrics used in the contest
Kind of dumb to mention this: I did not use the F1 score. Rather relied on accuracy.
Save as many things as I can so that you save time later
-
Save results
-
Save model
-
Save data
Use Checkpoints
- Did forget the idea of checkpoints entirely.
Useless Model
-
I made an ensemble which sucked because it only lead to 0.05 percent improvement.
-
The reason was I used a lot of mediocre models.
-
1 ResNet 34/50 would have been fine.
-
Also did not know about DenseNet very well back then.
-
I believe that an ensemble of ResNet and DenseNet would have been wonderful.
Data
Look at the data and use good augmentation
- I saw some images were grey scale and old. I might have got a higher score if I had taken time
Using good data augmentation.
My model was not performing well. 93—94% accuracy was the limit.
I buffed up every transformation. And it started reaching 96+. Warping helped a lot.

Developer Habits
- Start submissions early in the contest. And complete your work at least 3—4 days before the end.