· 6 min read
Create In-Memory Repository based on HashMap for Unit Tests Using Generative AI Instead of Mocking
Increasing accuracy of your Unit Tests and making them as easy to write as Integration Tests.
While integration tests are easier to write and more accurate, they are slower than unit tests. Each second added to the build time will stay with the application’s lifetime. 1 So, we want to prefer writing more unit tests.
We can write unit tests that are as accurate as integration tests if we don’t use mocks or use mocks minimally.
This article talks about creating a more accurate service layer test by creating an in-memory repository based on a hashmap instead of using the Integration test (@SpringBootTest) with a real database or Splice Test (@DataJpaTest) with an in-memory database.
Limitations of Mocked Unit Tests
When we mock, we provide the return value of the mock method. This means that the return value could be different. This means the accuracy of a mock-based unit test is totally dependent on the tester.
Also, mock tests involve a lot of mock-related code. We want to test the behaviour of the software, but it forces us to test the implementation.
Consider the writing test for the following class.
@Service
class MovieService{
@Autowired
private MovieRepository movieRepository;
List<Movie> getAllMoviesStartingWith(String prefix){
return movieRepository.findAllByNameStartsWith(prefix);
}
}If we want to test the service method with Mockito, we’d write something like this.
@Mock
MovieRepository movieRepository;
@InjectMock
MovieService movieService;
@Test
void testGetAllMoviesStartingWith() {
// given
String prefix = "Iron Man"; // Note the prefix being searched if different from movie names.
// i.e. changing the prefix won't affect the execution of the test.
List<Movie> expectedMovies = Arrays.asList(
new Movie("Star Wars"),
new Movie("Star Trek")
);
when(movieRepository.findAllByNameStartsWith(prefix)).thenReturn(expectedMovies);
// when
List<Movie> actualMovies = movieService.getAllMoviesStartingWith(prefix);
// then
assertEquals(expectedMovies, actualMovies);
verify(movieRepository, times(1)).findAllByNameStartsWith(prefix);
}As you can see, the prefix “Iron Man” differs from movie names, starting with “Star”. Since we provide the return value, we returned a different response than what might be.
Also, the when(movieRepository.findAllByNameStartsWith(prefix)).thenReturn(expectedMovies); part means our test is tied to implementation detail rather than the behaviour.
Since, we have to provide the mocked response and mock, these tests are harder to write as compared to integration tests where we just save and get from the repository directly.
In summary,
- Mocks provide predetermined return values, which might not reflect real scenarios.
- Mock-based tests are tied to implementation details, not behaviour.
- Writing and maintaining mock-related code can be cumbersome.
Benefits of Using a Custom InMemory Repository Implementation
If we have an in-memory implementation of a repository based on HashMap or any other collection,
- we could have the behaviour of a repository in Unit tests.
- we won’t have to
mock; we’ll be using the repository itself; it’s just a different implementation of the repository. - our tests would be as easy to write an integration or splice test, where we just save to the repository and get from repository.
- our test accuracy increases
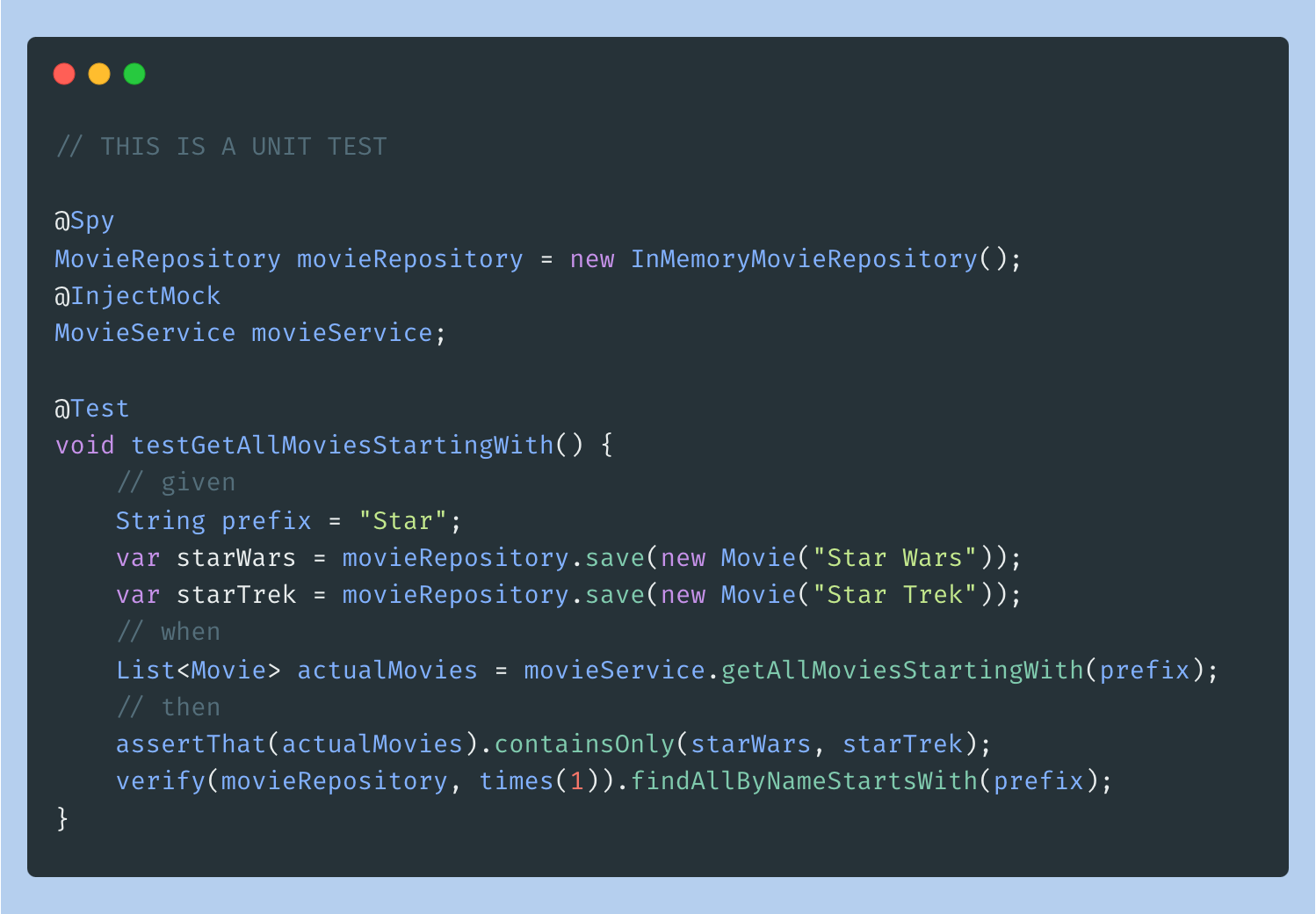
@Spy
MovieRepository movieRepository = new InMemoryMovieRepository();
@InjectMock
MovieService movieService;
@Test
void testGetAllMoviesStartingWith() {
// given
String prefix = "Star";
var starWars = movieRepository.save(new Movie("Star Wars"));
var starTrek = movieRepository.save(new Movie("Star Trek"));
// when
List<Movie> actualMovies = movieService.getAllMoviesStartingWith(prefix);
// then
assertThat(actualMovies).containsOnly(starWars, starTrek);
verify(movieRepository, times(1)).findAllByNameStartsWith(prefix);
}In the above, you’d have an integration test if you replace @Spy with either @Autowired or @SpyBean and replace @InjectMock with @Autowired.
What about Splice tests?
Splice tests like @DataMongoTest or @DataJpaTest can be a good alternative to Integration Test. For smaller projects, they can be an excellent alternative to unit tests with repositories, too.
In my testing, if @SpringBootTest took 16 seconds to start. @DataMongoTest took 3 seconds to start. In a large project with thousands of test files, you’d want to save that 3 seconds because it adds up quickly.
3 seconds *100 test classes = 5 minutes of startup time.
Granted, it won’t be 5 minutes in real life because spring caches test context.
Unit tests, on the other hand, are almost instantaneous and have the lowest execution time.
This article is written explicitly against the use of Mocks for repository tests. You can use Splice or the kind of InMemoryRepository suggested below.
Creating an InMemoryRepository using generative AI
Consider this simplistic implementation of the JpaRepository that can be generated with the help of an LLM, we’ll use the abstract class as a superclass for our custom repositories.
public abstract class InMemoryJpaRepository<T,ID> implements JpaRepository<T, Id>{
protected final Map<ID, T> inmemoryDatabase = new ConcurrentHashmap<>();
@override
T save(T entity){
Validator.validate(entity); // Simulating the validation that JPA does
inmemoryDatabase.put(entity.getId(), entity);
return entity;
}
@override
Optional<T> findById(ID id){
return Optional.nullable(inmemoryDatabase.getOrElse(id, null));
}
... other methods
}Consider your custom repository,
interface MovieRepository implements JPARepository<UUID, Movie>{
List<Movie> findAllByNameStartsWith(String prefix);
}You can have the implementation of it generated using an LLM.
import java.util.*;
import java.util.stream.Collectors;
public class InMemoryMovieRepository extends InMemoryJpaRepository<Movie, UUID> implements MovieRepository {
@Override
public List<Movie> findAllByNameStartsWith(String movieStartName) {
return inMemoryDatabase.values().stream()
.filter(movie -> movie.getName().startsWith(movieStartName))
.collect(Collectors.toList());
}
}If you are generating your repository using LLM, here are some tips:
- Create a base class in-memory version of
JpaRepositoryor whatever repository you use. Then, create your custom repositories. - For custom repositories such as LLM, add a Javadoc expressing one of the following, which will help keep track of the changes to the repository and generated code.
@Query method with {query}if the repository method is annotated with@QueryNormal Methodif the repository method is a normal method.
For More Accuracy of InMemory Repository
Add validation for your entity in your repository
Spring Data performs validation of your entities. Therefore, it makes sense that we perform that validation, too.
You should add validation whenever you get get or put in your Map instead of just validating when get.
Code sample:
T save(T entity){
validateEntity(entity);
store.put(entity.getId(), entity);
return entity;
}
Optional<T> findById(ID id){
return Optional.of(store.getOrDefault(id, null))
.map(this::validateEntity);
}
... other methods
void validateEntity(T entity){
ValidatorFactory factory = Validation.buildDefaultValidatorFactory();
Validator validator = factory.getValidator();
Set<ConstraintViolation<Person>> violations = validator.validate(entity);
if (!violations.isEmpty()) {
throw new ConstraintViolationException(violations);
}
}An even better implementation would be to create a wrapper class over Map and validate each time you get or put an entity into it.
Transactional
If you have a custom wrapper over the transactionTemplate, you can modify your InMemory repository to use it.
Ending
By adopting in-memory repositories for unit tests, we bridge the gap between the speed of unit tests and the accuracy of integration tests. This approach minimizes the dependency on mocks, resulting in more behavior-oriented and reliable tests. While integration tests are invaluable, their slower execution time can bottleneck in large projects. When designed with in-memory repositories, unit tests offer a practical solution that combines the best of both worlds.
Also, use an LLM to generate the code rather than write it yourself.
Resources & Citations
I came across two articles while searching for a readymade Spring Data Mock before using the Generative AI version.
- Mocking Spring Data repositories: Suggests something similar but using Mockito. The article is from a time when we didn’t have Generative AI (2015).
- github/mmnaseri/spring-data-mock: This would generate an inmemory implementation automatically but I this didn’t work for me. It may be because it doesn’t support Spring Boot 3.
Let me know if you liked this article. Check out TDD & Beyond series for similar articles
Footnotes
-
Paraphrasing Dmitry Bunin ↩