· 10 min read
Everything I know about Server-Side Caching
Boost application performance and scalability with effective caching strategies, from basic principles to advanced implementation in Spring Boot.
TLDR: Too many DB calls? Cache. When caching, limit to only essential fields.
Caching is one of those cool topics from the outside that’s simple on the inside. If you know memoization in dynamic programming, you know caching.
The general rule here is this.
When we have too many DB calls, we should cache.
A cache is just a fast storage device when you need performance.
In general, you should always rely on good database schema for performance. If something can’t be done with a good database schema or something requires a real-time update and sync, use a cache. You want to keep our system as small and light as possible, so if tuning your DB is enough for your performance, do that.
Below, I’ll talk about:
- Caching Basics
- What’s a Cache?
- What makes Cache Fast?
- Difference between Distributed Cache and Non-Distributed Cache
- Write Back Cache / Write Through Cache and How It Can Be Implemented in Spring Boot
- Thoughts on Implementation of Write Back Cache.
- Coding Specifics
- Write Back Cache / Write Through Cache and How It Can Be Implemented in Spring Boot
- Caching Limited Data
- Cache Key
- Caching Parameters
- TTL
- LIFO, FIFO, LFU
- Combination
- What about client caching vs server caching?
- Some Applications of Server Cache
- Authorization
- Real-Time Applications (Server Side; Distributed)
- Frequently used server data
- Frequently Accessed Page Data
Caching Basics
What’s a Cache?
A cache is data storage faster than a database that stores frequently used data, typically for a short period.
Consider a sports website where the score of a live game is displayed. If thousands of people are on the website, you want to avoid reading the data from the database each time because the database is designed well for long-term storage. You need a data storage that can quickly return value.
What makes Cache Fast?
The data in the database is stored on disk. Disks are slower than RAM. Caches are primarily in memory, which makes them really fast.
For instance, Redis, a famous distributed cache, is around 2x faster on write and 3x read than MongoDB as per a devs experiment
Caches are in RAM, so they are fast. At the same time, caches aren’t persistent, meaning if a cache server fails, the cache will be lost. Therefore, many caches provide the facility to flush data to disk, which can make them a bit fault-tolerant.
Difference between Distributed Cache and Non-Distributed Cache
A distributed cache is a cache shared between multiple systems. A non-distributed cache is a cache within the program itself and is not shared within the system.
Suppose you have three instances of an application, each reading data from the database. Whenever they read the database, they cache the value because we expect it to be reread.
Coding Specifics
Write-Back Cache / Write-Through Cache and how to implement in Spring Boot
If you want to update the data, what should you update first, the database or the cache? This leads us to two strategies for updating data in the cache.
- Write-Through: Write to the cache first and then in the database.
- Good when you have a real-time application.
- Write-Back: Write to the database first, then write the updated value in the cache. It’s simpler as most DBs are heavily constrained, meaning you don’t have to revert the cache if the DB update fails.
Implementing Write-Back Cache in Spring Boot
This is one of the ways to implement a write-back cache. You want to listen to changes made to the database and update the cache accordingly. Spring Boot provides an event lister to listen to whenever DB changes happen.
- Create an Entity Event Lister which listens to database changes
- Each time something is saved, update the database.
- You may want to skip updates depending on what you use the cache for.
- For instance, if you use a cache to store frequently used items, you may skip updating the cache for less frequent ones.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.CacheManager;
import org.springframework.context.event.EventListener;
import org.springframework.data.rest.core.event.AbstractRepositoryEventListener;
import org.springframework.stereotype.Component;
@Component
@RequiredArgsConstructor
public class UserEventListener extends AbstractRepositoryEventListener<User> {
private final CacheManager cacheManager;
@Override
protected void onAfterSave(User entity) {
cacheManager.getCache("users").put(entity.getId(), entity);
}
@Override
protected void onAfterDelete(User entity) {
cacheManager.getCache("users").evict(entity.getId());
}
}Spring Boot also has the following annotation to help with caching, which means you don’t have to use cacheManager directly.
@EnableCaching: Enables Spring’s annotation-driven cache management capability.@Cacheable: Caches the result of a method based on its parameters.@CachePut: Updates the cache with the method result, ensuring the method is always executed.@CacheEvict: Removes one or more entries from the cache, which is useful for clearing stale data.
Thoughts on the Implementation of Write-Through Cache
The implementation of a write-through cache would be something similar. The main difference is that the cache is rolled back if the database call fails.
This can’t be implemented with Database listeners.
Pseudocode:
// save to cache
// save to DB
//If DB fails, roll back the cache too.@Service
@RequiredArgsConstructor
public class UserService {
private final UserRepository userRepository;
private final CacheManager cacheManager;
@Cacheable(value = "users", key = "#id")
public User getUserById(Long id) {
return userRepository.findById(id).orElse(null);
}
public User saveUser(User user) {
Cache cache = cacheManager.getCache("users");
if (cache != null) {
Cache.ValueWrapper valueWrapper = cache.get(user.getId());
User cachedUser = valueWrapper != null ? (User) valueWrapper.get() : null;
// Save to cache first
cache.put(user.getId(), user);
// Save to DB
try {
return userRepository.save(user);
} catch (Exception e) {
// Rollback cache if DB save fails
if (cachedUser != null) {
cache.put(user.getId(), cachedUser);
} else {
cache.evict(user.getId());
}
throw e;
}
}
return userRepository.save(user); // Fallback if cache is not available
}
}Caching Limited Data
Caches have limited storage. So, you only want to cache what’s essential.
Typically, we only cache a limited amount of data or fields.
For example, if you want to display only the user’s first name, last name and image, you don’t need to cache in other values related to the user.
Cache Key
Unlike databases with multiple tables, most caches (like Redis) are a single giant key-value pair. This means you have to name the key in a way that helps you differentiate different types of data in the cache, or else your data will collide.
If you want to read more about cache keys, read my article: ”Crafting Unique ID from Composite Attributes for Key-Value Pairs (Redis, Map, and even Droppable-Id in React Beautiful DnD).”
Caching Terms
These are some standard terms you’ll see when using a cache.
Cache Hit:
- If the data we seek is found in the cache, we call it a cache hit.
Cache Miss:
- If the data we want to access is not found in the cache, we call it cache miss. We want to cache parameters such that we minimize cache miss.
Cache Evict:
- Removing data from the cache.
Cache Put:
- Adding Data to Cache
Cache Parameters
Caches usually have parameters associated with eviction. This is because caches are mostly in-memory (RAM), which is limited. After all, they are costly.
You can combine different parameters. For example, give a TTL of 4 seconds along with LFU.
-
TTL: Time To Live
- TTL defines how long data should be cached.
- After the TTL ends, the data will be removed from the cache.
-
Eviction Policy
- When the storage gets full, and a new item is to be inserted, remove either item that is
- LFU: Least Frequently Used
- if you want to cache the most frequently accessed
- LIFO: Last In, First Out
- FIFO: First In First Out
- if you expect something to be accessed only for a certain period, after which other items would be accessed
- LFU: Least Frequently Used
- When the storage gets full, and a new item is to be inserted, remove either item that is
You can combine different parameters. For example, give a TTL of 4 seconds along with LFU.
What about Client-side cache / server-side cache?
While this blog post talks about server-side cache, the concepts described are relevant to client-side caching, too.
Server Cache: A cache at the server side is called a server cache. This means the client would still hit the server and get the value. The server may not have to access the database; instead, it can get its value from the server’s cache.
Client Cache: Client cache is stored on the client side. Usually, static data like HTML, CSS, Javascript, and images are stored on the client, but operational data can also be stored.
Client Cache Parameters: The parameters (such as TTL) for client caches aare ultimately decided by the client. The server can hint to the client for ideal cache parameters, but ultimately, the client has control over what it wants to do with the cache.
All the concepts described above, such as cache parameters, write-through and write-back, apply to the client cache.
Synchronization: The client cache may want to sync up with the server to know if the cache has the latest value. In some caches, the server may push changes to clients using SSE (server send events) or WebSockets.
If you want to explore client-side caching related to web pages, google the following:
For client-side caching related to web pages, explore the following:
- HTTP Headers:
- ETag: A unique identifier for a specific version of a resource.
- Last-Modified: The date and time when the resource was last changed.
- Cache-Control: Directives for caching mechanisms in both requests and responses.
- Cache Max Age: Specifies the maximum amount of time a resource is considered fresh.
- HTTP Status Code 304: Indicates that the resource has not been modified, allowing the client to use the cached version.
- Browser Storage:
- Local Storage: Stores data with no expiration time, accessible by the client even after the browser is closed.
- Session Storage: Similar to local storage but only persists for the page session.
- IndexedDB: A low-level API for storing significant amounts of structured data, including files and blobs.
Some Applications of Server Cache
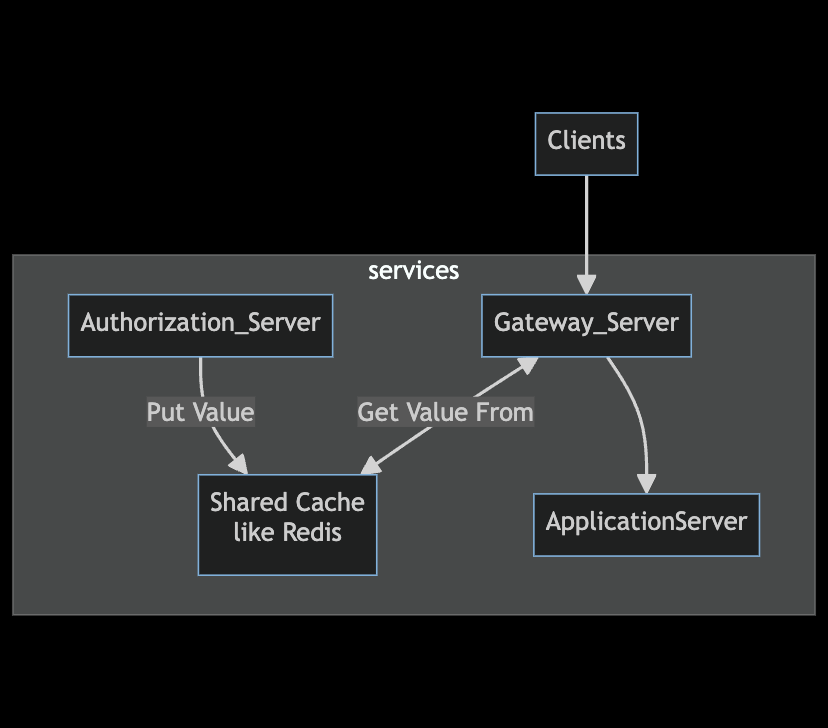
Authorization
You may use a cache to store the session value to maintain a user’s logged-in session.
- the authentication server stores the user’s details in the shared cache whenever the user logs in. Then, give the user a token.
- Whenever the user tries to access the application server, the gateway server will take the token from the request header and check the shared cache for user details against the token
- if found: The gateway server forwards the request to the application server
- else redirects to the authentication server for logging in.
To learn more, search “Redis for Session Management”.
Real-Time Applications (Server Side; Distributed)
If multiple users are using a system in real time, the data related to the session would be stored in the cache.
Consider an online game session like scribble.io. Instead of writing to the database, which would be slow, gameplay data would remain in RAM till the duration of the game.
Data which is accessed frequently by other services
Suppose you have something like user data that every microservice should access. Or it’s frequently accessed by users.
You could simply cache it.
Frequently Accessed Page Data
If you have an online store like Amazon with many products, you should cache the values on the first page.
Ending
Caching is an essential tool for improving the performance and scalability of applications.
By understanding and implementing the right caching strategies, you can reduce latency, handle higher loads, and provide a better user experience.
However, balancing caching and maintaining data consistency is crucial, ensuring your application remains robust and reliable.
Resources
- “Designing Data-Intensive Applications” by Martin Kleppmann
- Stack Overflow: Redis vs. MongoDB Performance - A discussion on the performance comparison between Redis and MongoDB.
- Crafting Unique ID from Composite Attributes for Key-Value Pairs (Redis, Map, and even Droppable-Id in React Beautiful DnD)
I hope this blog post helps you understand service-side caching better. If you want to improve the performance of your web application, consider reading the following blog posts: